EPT: Extended Page Table
This chapter covers EPT, the mechanism used to translate guest physical addresses to host physical addresses. By properly configuring EPT, you can provide the guest with a physical address space isolated from the host, to ensure that all access to physical addresses is under the host's control.
important
The source code for this chapter is in whiz-vmm-ept branch.
Table of Contents
- Overview of EPT
- Structure of EPT
- Creating Map
- EPTP
- Mapping Guest Physical Address
- Enabling EPT
- Unrestricted Guest
- VPID
- Summary
- References
Overview of EPT
In the previous chapters, the guest shared the physical address space with the host. The guest could access any physical address, including memory used by the host. If the guest runs malicious software, it could read arbitrary data from the host’s memory or overwrite the host’s data, potentially compromising the virtualization environment. This poses a serious security risk. The physical address space accessible to the guest should be isolated from the host, and the VMM must be able to manage this isolated space.
From here on, guest virtual addresses will be referred to as GVA, guest physical addresses as GPA, and host physical addresses as HPA.
EPT: Extended Page Table is a VT-x feature that supports virtualization of physical memory. EPT performs GPA to HPA translation, just as a regular page table translates HVA to HPA. When the guest accesses memory using a GVA, it first translates GVA to GPA using its page tables, and then GPA is translated to HPA via the EPT.
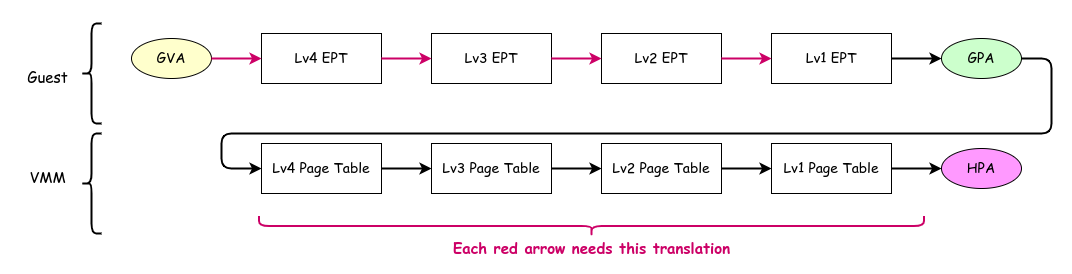 Address Translation Using EPT
Address Translation Using EPT
An important point to note is that GPA to HPA translation is also required when the guest accesses page tables for GVA to GPA translation. The guest’s CR3 holds the GPA of the level 4 page table needed for GVA to GPA translation, but before accessing this table, its GPA must be translated to HPA. In the diagram, the red references in the upper section (Guest) represent access to guest's page tables, while the lower section (VMM) shows the four corresponding accesses needed. Therefore, one guest page table lookup requires four EPT accesses (levels 4 through 1). This means that while normally four lookups suffice without virtualization, in a virtualized environment, 20 table lookups are required.
Of course, in practice, the number of lookups rarely gets this high thanks to the TLB. The TLB caches the results of both GVA to GPA and GPA to HPA translations. If both translations are cached in the TLB, address translation can be performed without any memory accesses, just like in a non-virtualized environment. (Strictly speaking, as explained later, the TLB also caches the results of GVA to HPA translations.)
Structure of EPT
GPA to HPA translation using EPT can be configured to use either 4 or 5 levels, similar to regular page tables. In this series, we adopt a 4-level EPT structure, just like the page tables.
The structure of EPT entries is similar to, or slightly simpler than, regular page table entries. Below is the structure representing an EPT entry. It is mostly the same as what was covered in the Paging chapter:
fn EntryBase(table_level: TableLevel) type {
return packed struct(u64) {
const Self = @This();
const level = table_level;
const LowerType = switch (level) {
.lv4 => Lv3Entry,
.lv3 => Lv2Entry,
.lv2 => Lv1Entry,
.lv1 => struct {},
};
/// Whether reads are allowed.
read: bool = true,
/// Whether writes are allowed.
write: bool = true,
/// If "mode-based execute control for EPT" is 0, execute access.
/// If that field is 1, execute access for supervisor-mode linear address.
exec_super: bool = true,
/// EPT memory type.
/// ReservedZ when the entry maps a page.
type: MemoryType = .uncacheable,
/// Ignore PAT memory type.
ignore_pat: bool = false,
/// If true, this entry maps memory. Otherwise, this references a page table.
map_memory: bool,
/// If EPTP[6] is 1, accessed flag. Otherwise, ignored.
accessed: bool = false,
// If EPTP[6] is 1, dirty flag. Otherwise, ignored.
dirty: bool = false,
/// Execute access for user-mode linear address.
exec_user: bool = true,
/// Ignored
_ignored2: u1 = 0,
/// 4KB aligned physical address of the mapped page or page table.
phys: u52,
/// Return true if the entry is present.
pub fn present(self: Self) bool {
return self.read or self.write or self.exec_super;
}
/// Get the physical address of the page or page table that this entry references or maps.
pub inline fn address(self: Self) Phys {
return @as(u64, @intCast(self.phys)) << page_shift_4k;
}
/// Get a new page table entry that references a page table.
pub fn newMapTable(table: []LowerType) Self {
if (level == .lv1) @compileError("Lv1 EPT entry cannot reference a page table");
return Self{
.map_memory = false,
.type = .uncacheable,
.phys = @truncate(virt2phys(table.ptr) >> page_shift_4k),
};
}
/// Get a new page table entry that maps a page.
pub fn newMapPage(phys: Phys) Self {
if (level == .lv4) @compileError("Lv4 EPT entry cannot map a page");
return Self{
.read = true,
.write = true,
.exec_super = true,
.exec_user = true,
.map_memory = true,
.type = @enumFromInt(0),
.phys = @truncate(virt2phys(phys) >> page_shift_4k),
};
}
};
}
const Lv4Entry = EntryBase(.lv4);
const Lv3Entry = EntryBase(.lv3);
const Lv2Entry = EntryBase(.lv2);
const Lv1Entry = EntryBase(.lv1);
const MemoryType = enum(u3) {
uncacheable = 0,
write_back = 6,
};
const TableLevel = enum {
lv4,
lv3,
lv2,
lv1,
};
Since entries from Lv4 to Lv1 have roughly the same structure, this series uses a unified struct for them, just like with the page tables.
A key difference from regular page tables is the absence of the present bit. Instead, if all three bits representing RWX permissions are 0, the entry is considered not present.
Creating Map
As mentioned earlier, address translation with EPT enabled significantly increases the number of table lookups, resulting in poor efficiency. The simplest countermeasure is to use the largest possible EPT pages. In Ymir, we will use only 2MiB EPT pages. GPA to HPA translation of a 2MiB page completes by referencing up to the Lv2 entry. Since this reduces the GPA to HPA translation to just three memory accesses, the number of lookups is reduced to 3/4 compared to a full 4-level translation1.
The function that maps 2MiB pages is shown below. As I’ve said many times, it’s really the same as with page tables2:
fn map2m(gpa: Phys, hpa: Phys, lv4tbl: []Lv4Entry, allocator: Allocator) Error!void {
const lv4index = (gpa >> lv4_shift) & index_mask;
const lv4ent = &lv4tbl[lv4index];
if (!lv4ent.present()) {
const lv3tbl = try initTable(Lv3Entry, allocator);
lv4ent.* = Lv4Entry.newMapTable(lv3tbl);
}
const lv3ent = getLv3Entry(gpa, lv4ent.address());
if (!lv3ent.present()) {
const lv2tbl = try initTable(Lv2Entry, allocator);
lv3ent.* = Lv3Entry.newMapTable(lv2tbl);
}
if (lv3ent.map_memory) return error.AlreadyMapped;
const lv2ent = getLv2Entry(gpa, lv3ent.address());
if (lv2ent.present()) return error.AlreadyMapped;
lv2ent.* = Lv2Entry{
.map_memory = true,
.phys = @truncate(hpa >> page_shift_4k),
};
}
initTable() allocates a page from the Allocator and initializes 512 entries as non-present:
fn initTable(T: type, allocator: Allocator) Error![]T {
const tbl = try allocator.alloc(T, num_table_entries);
for (0..tbl.len) |i| {
tbl[i].read = false;
tbl[i].write = false;
tbl[i].exec_super = false;
tbl[i].map_memory = false;
tbl[i].type = @enumFromInt(0);
}
return tbl;
}
Constants like lv4_shift and functions such as getLv3Entry() are the same as those defined for the host page tables in ymir/arch/x86/page.zig. For details, please refer to the GitHub repository.
EPTP
In paging, the CR3 register holds the address of the level 4 page table (plus some additional info). Similarly, the address of the level 4 EPT table is stored in the EPTP: Extended Page Table Pointer. EPTP has the following format. For reference, the formats of each EPT level are also provided:
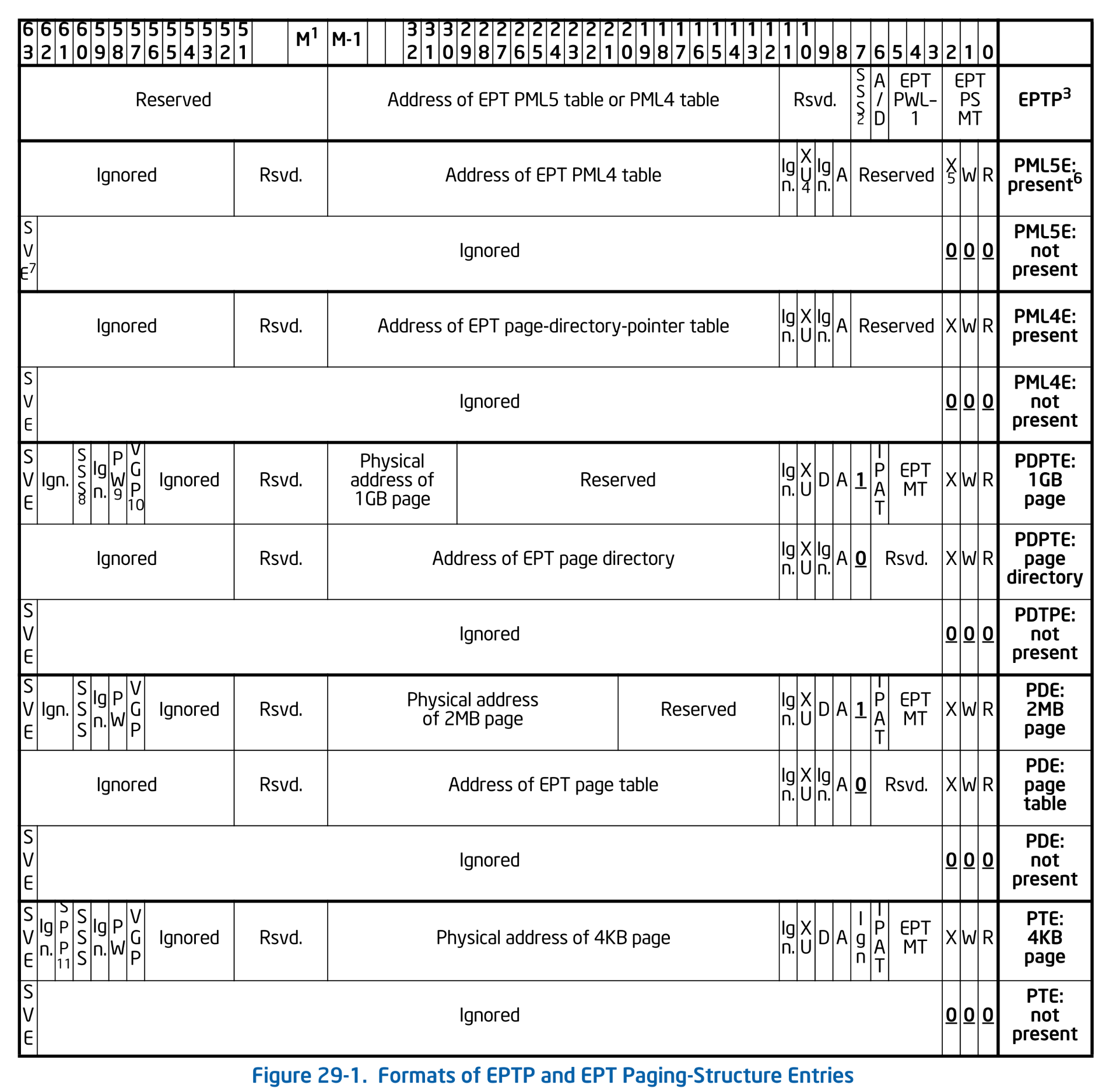 Formats of EPTP and EPT Paging Structure Entries. SDM Vol.3C 29.3.3 Figure 29-1.
Formats of EPTP and EPT Paging Structure Entries. SDM Vol.3C 29.3.3 Figure 29-1.
We define Eptp according to the format. This struct takes the level 4 table address as an argument in new(). Note that the level 4 table address stored in EPTP, like CR3, is a physical address (HPA):
pub const Eptp = packed struct(u64) {
/// Memory type.
type: MemoryType = .write_back,
/// EPT page-walk length.
level: PageLevel = .four,
/// Enable dirty and accessed flags for EPT.
enable_ad: bool = true,
/// Enable enforcement of access rights for supervisor shadow-stack pages.
enable_ar: bool = false,
/// Reserved.
_reserved1: u4 = 0,
/// 4KB aligned address of the Level-4 EPT table.
phys: u52,
pub fn new(lv4tbl: []Lv4Entry) Eptp {
return Eptp{
.phys = @truncate(virt2phys(lv4tbl.ptr) >> page_shift_4k),
};
}
/// Get the host virtual address of the Level-4 EPT table.
pub fn getLv4(self: *Eptp) []Lv4Entry {
const virt: [*]Lv4Entry = @ptrFromInt(phys2virt(@as(u64, @intCast(self.phys)) << page_shift_4k));
return virt[0..num_table_entries];
}
const PageLevel = enum(u3) {
four = 3,
five = 4,
};
};
Mapping Guest Physical Address
Now, let's use EPT to map physical addresses for the guest.
There are various ways to manage EPT. A common approach, similar to regular page tables, is to initially map only the necessary pages and allocate physical memory on demand when a fault occurs on unmapped pages. When the guest tries to access an unmapped GPA, a VM Exit occurs. This triggers the VMM to allocate physical memory only as needed. The advantage of this method is that physical memory is allocated only for what the guest actually uses. Memory that the guest never accesses can be used by other guests or the host.
Ymir adopts a different approach. In the Paging chapter, all available virtual addresses were mapped to physical pages during page table initialization. As a result, Ymir never encounters page faults. If one occurs, it indicates a bug and is treated as unrecoverable, leading to an abort. This approach is similar to Linux kernel. Following this, Ymir maps all guest's physical addresses before the guest starts running. Therefore, EPT violations never occur. Once EPT is initialized, it is never modified again.
In this series, we allocate a fixed 100MiB of memory to the guest. Ymir itself is configured via QEMU startup options to use 512MiB of memory. Even after allocating 100MiB to the guest, Ymir can still use 412MiB, which is more than enough3.
Add a member guest_mem to the Vm struct to hold the guest memory, and add a function to initialize the guest memory:
const guest_memory_size = 100 * mem.mib;
pub const Vm = struct {
guest_mem: []u8 = undefined,
...
pub fn setupGuestMemory(
self: *Self,
allocator: Allocator,
page_allocator: *PageAllocator,
) Error!void {
// Allocate guest memory.
self.guest_mem = page_allocator.allocPages(
guest_memory_size / mem.page_size_4k,
mem.page_size_2mb, // This alignment is required because EPT uses only 2MiB pages.
) orelse return Error.OutOfMemory;
// Create simple EPT mapping.
const eptp = try impl.mapGuest(self.guest_mem, allocator);
try self.vcpu.setEptp(eptp, self.guest_mem.ptr);
log.info("Guest memory is mapped: HVA=0x{X:0>16} (size=0x{X})", .{ @intFromPtr(self.guest_mem.ptr), self.guest_mem.len });
}
};
We allocate a contiguous 100MiB region. Although contiguity is not strictly necessary, it simplifies setting up the EPT tables. Also, to use only 2MiB pages, the allocated region must be aligned to 2MiB. Since the Allocator interface does not support allocations with alignment larger than one page size, we reluctantly accept a PageAllocator instance directly as an argument.
After allocating the memory, call arch.vmx.mapGuest() to initialize the EPT based on the allocated region. This function is just a wrapper to avoid exposing arch.vmx.ept throughout Ymir:
pub fn mapGuest(host_pages: []u8, allocator: Allocator) VmxError!ept.Eptp {
return ept.initEpt(
0,
mem.virt2phys(host_pages.ptr),
host_pages.len,
allocator,
);
}
The implementation is ept.initEpt():
pub fn initEpt(
/// Guest physical address to map.
guest_start: Phys,
/// Host physical address to map.
host_start: Phys,
/// Size in bytes of the memory region to map.
size: usize,
/// Page allocator.
allocator: Allocator,
) Error!Eptp {
const lv4tbl = try initTable(Lv4Entry, allocator);
log.debug("EPT Level4 Table @ {X:0>16}", .{@intFromPtr(lv4tbl.ptr)});
for (0..size / page_size_2mb) |i| {
try map2m(
guest_start + page_size_2mb * i,
host_start + page_size_2mb * i,
lv4tbl,
allocator,
);
}
return Eptp.new(lv4tbl);
}
Calculate the number of 2MiB pages required based on the guest memory size, and call the previously implemented map2m() that many times.
これらの関数は、VMX Root Operation に入った後 VM を起動する前に kernelMain() から呼び出します:
fn kernelMain(boot_info: surtr.BootInfo) !void {
...
try vm.setupGuestMemory(general_allocator, &mem.page_allocator_instance);
log.info("Setup guest memory.", .{});
...
}
This completes the mapping of guest physical memory. Since we now have the EPTP pointing to the Lv4 EPT table, set it in the VMCS Execution Control. Because EPTP is maintained per vCPU, it makes sense to also store guest memory information in the Vcpu struct:
pub const Vcpu = struct {
eptp: ept.Eptp = undefined,
guest_base: Phys = undefined,
...
pub fn setEptp(self: *Self, eptp: ept.Eptp, host_start: [*]u8) VmxError!void {
self.eptp = eptp;
self.guest_base = ymir.mem.virt2phys(host_start);
try vmwrite(vmcs.ctrl.eptp, eptp);
}
...
}
Enabling EPT
EPTP does not become effective just by setting it. You need to enable the bit for Secondary Processor-Based VM-Execution Control in the VMCS Execution Control category. This field, like Primary Processor-Based VM-Execution Control, mainly controls the vCPU behavior related to synchronous events. Since this field hasn't been used before, let's define a struct for it:
pub const SecondaryProcExecCtrl = packed struct(u32) {
const Self = @This();
virtualize_apic_accesses: bool,
ept: bool,
descriptor_table: bool,
rdtscp: bool,
virtualize_x2apic_mode: bool,
vpid: bool,
wbinvd: bool,
unrestricted_guest: bool,
apic_register_virtualization: bool,
virtual_interrupt_delivery: bool,
pause_loop: bool,
rdrand: bool,
enable_invpcid: bool,
enable_vmfunc: bool,
vmcs_shadowing: bool,
enable_encls: bool,
rdseed: bool,
enable_pml: bool,
ept_violation: bool,
conceal_vmx_from_pt: bool,
enable_xsaves_xrstors: bool,
pasid_translation: bool,
mode_based_control_ept: bool,
subpage_write_eptr: bool,
pt_guest_pa: bool,
tsc_scaling: bool,
enable_user_wait_pause: bool,
enable_pconfig: bool,
enable_enclv: bool,
_reserved1: u1,
vmm_buslock_detect: bool,
instruction_timeout: bool,
pub fn load(self: Self) VmxError!void {
const val: u32 = @bitCast(self);
try vmx.vmwrite(ctrl.secondary_proc_exec_ctrl, val);
}
pub fn store() VmxError!Self {
const val: u32 = @truncate(try vmx.vmread(ctrl.secondary_proc_exec_ctrl));
return @bitCast(val);
}
};
To enable EPT, set the .ept bit. Like other Execution Control fields, whether to clear or set reserved bits depends on the MSR. For Secondary Processor-Based Control, query the IA32_VMX_PROCBASED_CTLS2 MSR (address 0x048B):
fn setupExecCtrls(vcpu: *Vcpu, allocator: Allocator) VmxError!void {
...
ppb_exec_ctrl.activate_secondary_controls = true;
...
var ppb_exec_ctrl2 = try vmcs.SecondaryProcExecCtrl.store();
ppb_exec_ctrl2.ept = true;
try adjustRegMandatoryBits(
ppb_exec_ctrl2,
am.readMsr(.vmx_procbased_ctls2),
).load();
}
Unrestricted Guest
We will verify that EPT has been enabled. Up to this chapter, the guest ran blobGuest() while sharing the address space with the host. Once EPT is enabled, the guest and host address spaces are separated, so the guest can no longer execute blobGuest() located in the host’s address space. If you try to run the guest’s blobGuest() as before, the address registered in VMCS RIP is interpreted as a GVA. This is translated to a GPA by the guest’s page tables stored in CR3, and then further translated to an HPA by EPT. As a result, RIP no longer points to the HPA of blobGuest().
Strictly speaking, the physical address stored in CR3 itself is interpreted as a GPA and further translated by EPT, so the guest can no longer access the page tables or even perform GVA to GPA translation for RIP. This means it cannot access any address at all. Attempting to execute even a single instruction causes a page fault, and since its handler cannot run either, the system immediately triggers a triple fault and crashes. Under these conditions, the guest program cannot be executed.
From this chapter onward, the guest will run as an unrestricted guest. The guest we ran until now was a restricted guest. Restricted guests cannot disable paging or operate in real mode. In contrast, unrestricted guests can disable paging and run in real mode. By switching to unrestricted guest mode and disabling paging, we effectively disable GVA to GPA translation for the guest, allowing at least memory access to work.
As a general approach, before running the guest, copy blobGuest() directly from the host to the guest's memory. To make it clear, if you copy blobGuest() to the beginning of guest memory, setting VMCS RIP to 0 allows the guest to execute blobGuest().
First, let's enable unrestricted guest mode:
fn setupExecCtrls(_: *Vcpu, _: Allocator) VmxError!void {
...
ppb_exec_ctrl2.unrestricted_guest = true;
...
}
Then, we disable IA-32e mode on VM Entry:
fn setupEntryCtrls(_: *Vcpu) VmxError!void {
...
entry_ctrl.ia32e_mode_guest = false;
...
}
After that, we disable paging by setting CR0 in the Guest State:
fn setupGuestState(_: *Vcpu) VmxError!void {
...
var cr0 = std.mem.zeroes(am.Cr0);
cr0.pe = true; // Protected-mode
cr0.ne = true; // Numeric error
cr0.pg = false; // Paging
try vmwrite(vmcs.guest.cr0, cr0);
...
}
CR0の定義
/// CR0 register.
pub const Cr0 = packed struct(u64) {
/// Protected mode enable.
pe: bool,
/// Monitor co-processor.
mp: bool,
/// Emulation.
em: bool,
/// Task switched.
ts: bool,
/// Extension type.
et: bool,
/// Numeric error.
ne: bool,
/// Reserved.
_reserved1: u10 = 0,
/// Write protect.
wp: bool,
/// Reserved.
_reserved2: u1 = 0,
/// Alignment mask.
am: bool,
/// Reserved.
_reserved3: u10 = 0,
/// Not-Write Through.
nw: bool,
/// Cache disable.
cd: bool,
/// Paging.
pg: bool,
/// Reserved.
_reserved4: u32 = 0,
};
This completes setting the guest as unrestricted guest with paging disabled. Finally, copy blobGuest() to guest memory and set VMCS RIP to 0:
pub fn loop(self: *Self) VmxError!void {
const func: [*]const u8 = @ptrCast(&blobGuest);
const guest_map: [*]u8 = @ptrFromInt(mem.phys2virt(self.guest_base));
@memcpy(guest_map[0..0x20], func[0..0x20]);
try vmwrite(vmcs.guest.rip, 0);
...
}
The copy size of 0x20 is arbitrary. Since blobGuest() currently only runs an HLT loop, it should consist of just two instructions: hlt and jmp, so this many bytes aren’t really necessary. Well, you can never have too many of these.
ffffffff80115f20 <blobGuest>:
ffffffff80115f20: eb 00 jmp ffffffff80115f22 <blobGuest+0x2>
ffffffff80115f22: f4 hlt
ffffffff80115f23: eb fd jmp ffffffff80115f22 <blobGuest+0x2>
Okay, let's run the guest. Output would looks like below:
[INFO ] main | Entered VMX root operation.
[DEBUG] ept | EPT Level4 Table @ FFFF88800000A000
[INFO ] vmx | Guest memory is mapped: HVA=0xFFFF888000A00000 (size=0x6400000)
[INFO ] main | Setup guest memory.
[INFO ] main | Starting the virtual machine...
There are no crashes or VMX Exits occurring. It appears to have successfully entered the HLT loop. Running info registers in the QEMU monitor shows the following:
EAX=00000000 EBX=00000000 ECX=00000000 EDX=00000000
ESI=00000000 EDI=00000000 EBP=00000000 ESP=00000000
EIP=00000003 EFL=00000002 [-------] CPL=0 II=0 A20=1 SMM=0 HLT=1
ES =0000 00000000 ffffffff 00c09300 DPL=0 DS [-WA]
CS =0010 00000000 ffffffff 00a09b00 DPL=0 CS64 [-RA]
SS =0000 00000000 ffffffff 00c09300 DPL=0 DS [-WA]
DS =0000 00000000 ffffffff 00c09300 DPL=0 DS [-WA]
FS =0000 00000000 ffffffff 00c09300 DPL=0 DS [-WA]
GS =0000 00000000 ffffffff 00c09300 DPL=0 DS [-WA]
LDT=0000 00dead00 00000000 00008200 DPL=0 LDT
TR =0000 00000000 00000000 00008b00 DPL=0 TSS32-busy
GDT= 00000000 00000000
IDT= 00000000 00000000
CR0=00000031 CR2=00000000 CR3=00001000 CR4=00002668
RIP is set to 0x3, which, according to the earlier objdump result, corresponds to the JMP instruction. This confirms that the guest has properly entered the HLT loop. Additionally, the guest marker 0xDEAD00 is set in the LDT, indicating that EPT is enabled and GPA is being translated to HPA.
VPID
Finally, let's briefly touch on VPID, an important feature when using EPT.
A major issue when using EPT is the timing of TLB flushes. Utilizing EPT means that the TLB caches entries from both the host and guest virtual address spaces. Older architectures couldn’t distinguish whether a TLB entry belonged to the host or guest address space. If the TLB was used as is, the host might end up using TLB entries from the guest’s address space. This would cause incorrect address translations and break the program. To prevent this, all TLB entries were flushed whenever transitioning between VMX Non-root Operation and VMX Root Operation.
To avoid unnecessary TLB flushes, later CPUs introduced VPID: Virtual Processor Identifier. VPID is a unique 16-bit ID assigned to each vCPU (and logical core), separating the TLB namespace between VMs (and the host). Enabling VPID prevents accidentally using cached address translations from another VM or the host. As a result, there is no longer a need to flush the TLB when switching between VMX Non-root Operation and VMX Root Operation.
The host is automatically assigned VPID 0. Each vCPU must be explicitly assigned a unique VPID starting from 1. If you mistakenly assign 0 as a guest’s VPID, VM Entry will fail. Conversely, if different guests unintentionally share the same VPID, they will use the same TLB entries, causing bugs.
Information to be Cached
When enabling EPT and VPID, there are three types of information cached in the TLB4:
- Linear Mappings: The results of GVA to GPA (= HPA) translations, along with the page table entries used for those translations.
- Guest-Physical Mappings: The results of GPA to HPA translations, along with the page table entries used for those translations.
- Combined Mappings: The results of GVA to HPA translations, along with the page table entries used for those translations.
Each mapping cache includes not only the address translation results but also information such as memory type and access permissions. For combined mappings, the cached memory type and access permissions reflect the combination of both the page tables and the EPT.
When the guest performs memory access, each mapping is used as follows:
- When EPT is disabled: Linear mappings tagged with VPID and PCID are used.
- When EPT is enabled:
- Virtual address: Combined mappings tagged with VPID, PCID, and EPTRTA5 are used.
- Physical address: Guest-physical mappings tagged with EPTRTA are used.
The methods to invalidate these caches and the mappings that get invalidated are as follows:
- Operations that flush the TLB regardless of VMX operations: Linear + Combined (tagged with VPID)
- EPT Violation: Guest-physical mappings used by the translations (tagged with EPTRTA) + combined mappings (tagged with PCID + VPID + EPTRTA).
- VM Entry/Exit (when VPID is disabled): Linear(tagged with VPID=0) + combined mapping (tagged with VPID=0)
- INVVPID / INVEPT: Specified cache
Enabling VPID
In Ymir, to avoid flushing the TLB on every VMX transition, VPID is enabled. First, you need to check whether VPID is supported. This can be done by checking the IA32_VMX_EPT_VPID_CAP_MSR (0x048C):
IA32_VMX_EPT_VPID_CAP_MSR MSR の構造
pub const MsrVmxEptVpidCap = packed struct(u64) {
ept_exec_only: bool,
_reserved1: u5 = 0,
ept_lv4: bool,
ept_lv5: bool,
ept_uc: bool,
_reserved2: u5 = 0,
ept_wb: bool,
_reserved3: u1 = 0,
ept_2m: bool,
ept_1g: bool,
_reserved4: u2 = 0,
invept: bool,
ept_dirty: bool,
ept_advanced_exit: bool,
shadow_stack: bool,
_reserved5: u1 = 0,
invept_single: bool,
invept_all: bool,
_reserved6: u5 = 0,
invvpid: bool,
_reserved7: u7 = 0,
invvpid_individual: bool,
invvpid_single: bool,
invvpid_all: bool,
invvpid_single_globals: bool,
_reserved8: u4 = 0,
hlat_prefix: u6,
_reserved9: u10 = 0,
};
In Ymir, VPID is considered supported only if all options of INVVPID instruction are supported.
fn isVpidSupported() bool {
const cap: am.MsrVmxEptVpidCap = @bitCast(am.readMsr(.vmx_ept_vpid_cap));
return cap.invvpid and cap.invvpid_single and cap.invvpid_all and cap.invvpid_individual and cap.invvpid_single_globals;
}
To enable VPID, set the vpid bit in Secondary Processor-Based VM-Execution Control. Additionally, the vCPU's VPID should be set in the dedicated field of VMCS Execution Control.
fn setupExecCtrls(vcpu: *Vcpu, _: Allocator) VmxError!void {
...
ppb_exec_ctrl2.vpid = isVpidSupported();
...
if (isVpidSupported()) {
try vmwrite(vmcs.ctrl.vpid, vcpu.vpid);
}
}
Since this series handles only one core, the vpid in Vcpu is fixed to 1. When dealing with multiple vCPUs, each must be assigned a unique VPID.
Summary
In this chapter, we separated the host and guest address spaces by enabling EPT. Ymir adopts the policy of mapping all guest memory using 2MiB pages before the guest starts. Additionally, by enabling VPID, TLB flushes during VMX transitions are avoided. We successfully ran the guest in a separated address space and confirmed it entered the HLT loop.
In the next chapter, we will load Linux kernel into the prepared guest memory and prepare for booting Linux.
References
- MMU Virtualization via Intel EPT: Technical Details - Reverse Entineering
- Hypervisor From Scratch – Part 8: How To Do Magic With Hypervisor! - Rayanfam Blog
- ちょっと詳しいEPT - おしぼり / Zenn
That’s the official reason, but the real one is that it makes implementing EPT simpler.
Since the implementations of EPT and page tables are quite similar, it might actually be better to unify them to some extent.
It's more than enough - and actually wasteful - that Ymir, which does almost nothing, occupies 412MiB, so it's safe to allocate more to the guest.
SDM Vol.3C 29.4.1 Information That May Be Cached
EPT Root Table Address: The address of the Lv4 table in EPT.